




This article was co-authored by Andrew Ansley.
Things, not strings. If you haven’t heard this before, it comes from a famous Google blog post that announced the Knowledge Graph.
The announcement’s 11th anniversary is only a month away, yet many still struggle to understand what “things, not strings” really means for SEO.
The quote is an attempt to convey that Google understands things and is no longer a simple keyword detection algorithm.
In May 2012, one could argue that entity SEO was born. Google’s machine learning, aided by semi-structured and structured knowledge bases, could understand the meaning behind a keyword.
The ambiguous nature of language finally had a long-term solution.
So if entities have been important for Google for over a decade, why are SEOs still confused about entities?
Good question. I see four reasons:
- Entity SEO as a term has not been used widely enough for SEOs to become comfortable with its definition and therefore incorporate it into their vocabulary.
- Optimizing for entities greatly overlaps with the old keyword-focused optimization methods. As a result, entities get conflated with keywords. On top of this, it was not clear how entities played a role in SEO, and the word “entities” is sometimes interchangeable with “topics” when Google speaks on the subject.
- Understanding entities is a boring task. If you want deep knowledge of entities, you’ll need to read some Google patents and know the basics of machine learning. Entity SEO is a far more scientific approach to SEO – and science just isn’t for everyone.
- While YouTube has massively impacted knowledge distribution, it has flattened the learning experience for many subjects. The creators with the most success on the platform have historically taken the easy route when educating their audience. As a result, content creators haven’t spent much time on entities until recently. Because of this, you need to learn about entities from NLP researchers, and then you need to apply the knowledge to SEO. Patents and research papers are key. Once again, this reinforces the first point above.
This article is a solution to all four problems that have prevented SEOs from fully mastering an entity-based approach to SEO.
By reading this, you’ll learn:
- What an entity is and why it’s important.
- The history of semantic search.
- How to identify and use entities in the SERP.
- How to use entities to rank web content.
Why are entities important?
Entity SEO is the future of where search engines are headed with regard to choosing what content to rank and determining its meaning.
Combine this with knowledge-based trust, and I believe that entity SEO will be the future of how SEO is done in the next two years.
Examples of entities
So how do you recognize an entity?
The SERP has several examples of entities that you’ve likely seen.
The most common types of entities are related to locations, people, or businesses.
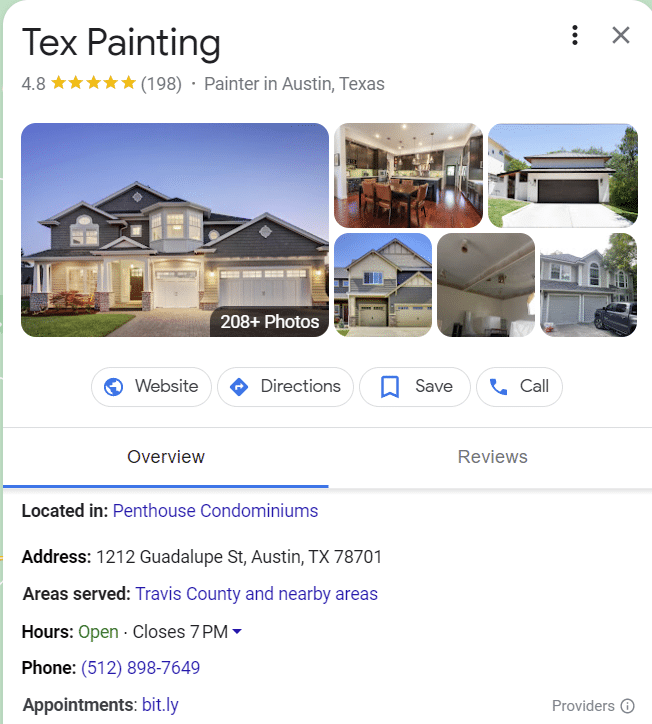

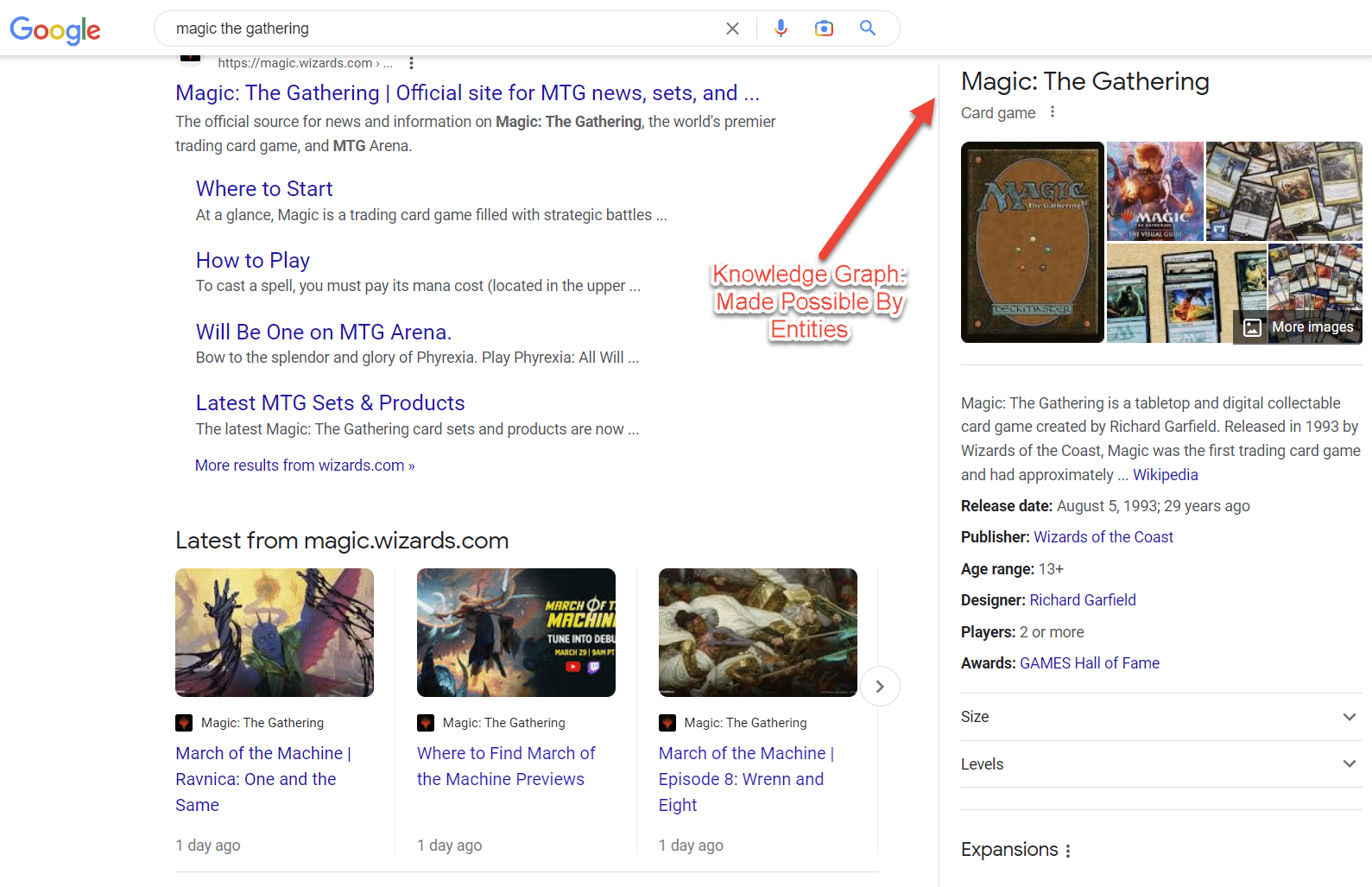
Perhaps the best example of entities in the SERP is intent clusters. The more a topic is understood, the more these search features emerge.
Interestingly enough, a single SEO campaign can alter the face of the SERP when you know how to execute entity-focused SEO campaigns.
Wikipedia entries are another example of entities. Wikipedia provides a great example of information associated with entities.
As you can see from the top left, the entity has all sorts of attributes associated with “fish,” ranging from its anatomy to its importance to humans.

While Wikipedia contains many data points on a topic, it is by no means exhaustive.
What is an entity?
An entity is a uniquely identifiable object or thing characterized by its name(s), type(s), attributes, and relationships to other entities. An entity is only considered to exist when it exists in an entity catalog.
Entity catalogs assign a unique ID to each entity. My agency has programmatic solutions that use the unique ID associated with each entity (services, products, and brands are all included).
If a word or phrase is not inside an existing catalog, it does not mean that the word or phrase is not an entity, but you can typically know whether something is an entity by its existence in the catalog.
It is important to note that Wikipedia is not the deciding factor on whether something is an entity, but the company is most well-known for its database of entities.
Any catalog can be used when talking about entities. Typically, an entity is a person, place, or thing, but ideas and concepts can also be included.
Some examples of entity catalogs include:
- Wikipedia
- Wikidata
- DBpedia
- Freebase
- Yago

Entities help to bridge the gap between the worlds of unstructured and structured data.
They can be used to semantically enrich unstructured text, while textual sources may be utilized to populate structured knowledge bases.
Recognizing mentions of entities in text and associating these mentions with the corresponding entries in a knowledge base is known as the task of entity linking.
Entities allow for a better understanding of the meaning of text, both for humans and for machines.
While humans can relatively easily resolve the ambiguity of entities based on the context in which they are mentioned, this presents many difficulties and challenges for machines.
The knowledge base entry of an entity summarizes what we know about that entity.
As the world is constantly changing, so are new facts surfacing. Keeping up with these changes requires a continuous effort from editors and content managers. This is a demanding task at scale.
By analyzing the contents of documents in which entities are mentioned, the process of finding new facts or facts that need updating may be supported or even fully automated.
Scientists refer to this as the problem of knowledge base population, which is why entity linking is important.
Entities facilitate a semantic understanding of the user’s information need, as expressed by the keyword query, and the document’s content. Entities thus may be used to improve query and/or document representations.
In the Extended Named Entity research paper, the author identifies around 160 entity types. Here are two of seven screenshots from the list.


Certain categories of entities are more easily defined, but it’s important to remember that concepts and ideas are entities. Those two categories are very difficult for Google to scale on its own.
You can’t teach Google with just a single page when working with vague concepts. Entity understanding requires many articles and many references sustained over time.
Google’s history with entities
On July 16, 2010, Google purchased Freebase. This purchase was the first major step that led to the current entity search system.

After investing in Freebase, Google realized that Wikidata had a better solution. Google then worked to merge Freebase into Wikidata, a task that was far more difficult than expected.
Five Google scientists wrote a paper titled “From Freebase to Wikidata: The Great Migration.” Key takeaways include.
“Freebase is built on the notions of objects, facts, types, and properties. Each Freebase object has a stable identifier called a “mid” (for Machine ID).”
“Wikidata’s data model relies on the notions of item and statement. An item represents an entity, has a stable identifier called “qid”, and may have labels, descriptions, and aliases in multiple languages; further statements and links to pages about the entity in other Wikimedia projects – most prominently Wikipedia. Contrary to Freebase, Wikidata statements do not aim to encode true facts, but claims from different sources, which can also contradict each other…”
Entities are defined in these knowledge bases, but Google still had to build its entity knowledge for unstructured data (i.e., blogs).
Google partnered with Bing and Yahoo and created Schema.org to accomplish this task.
Google provides schema directions so website managers can have tools that help Google understand the content. Remember, Google wants to focus on things, not strings.
In Google’s words:
“You can help us by providing explicit clues about the meaning of a page to Google by including structured data on the page. Structured data is a standardized format for providing information about a page and classifying the page content; for example, on a recipe page, what are the ingredients, the cooking time and temperature, the calories, and so on.”
Google continues by saying:
“You must include all the required properties for an object to be eligible for appearance in Google Search with enhanced display. In general, defining more recommended features can make it more likely that your information can appear in Search results with enhanced display. However, it is more important to supply fewer but complete and accurate recommended properties rather than trying to provide every possible recommended property with less complete, badly-formed, or inaccurate data.”
More could be said about schema, but suffice it to say schema is an incredible tool for SEOs looking to make page content clear to search engines.
The last piece of the puzzle comes from Google’s blog announcement titled “Improving Search for The Next 20 Years.”
Document relevance and quality are the main ideas behind this announcement. The first method Google used for determining the content of a page was entirely focused on keywords.
Google then added topic layers to search. This layer was made possible by knowledge graphs and by systematically scraping and structuring data across the web.
That brings us to the current search system. Google went from 570 million entities and 18 billion facts to 800 billion facts and 8 billion entities in less than 10 years. As this number grows, entity search improves.
How is the entity model an improvement from previous search models?
Traditional keyword-based information retrieval (IR) models have an inherent limitation of not being able to retrieve (relevant) documents that have no explicit term matches with the query.
If you use ctrl + f to find text on a page, you use something similar to the traditional keyword-based information retrieval model.
An insane amount of data is published on the web every day.
It simply isn’t feasible for Google to understand the meaning of every word, every paragraph, every article, and every website.
Instead, entities provide a structure from which Google can minimize the computational load while improving understanding.
“Concept-based retrieval methods attempt to tackle this challenge by relying on auxiliary structures to obtain semantic representations of queries and documents in a higher-level concept space. Such structures include controlled vocabularies (dictionaries and thesauri), ontologies, and entities from a knowledge repository.”
– Entity-Oriented Search, Chapter 8.3
Krisztian Balog, who wrote the definitive book on entities, identifies three possible solutions to the traditional information retrieval model.
- Expansion-based: Uses entities as a source for expanding the query with different terms.
- Projection-based: The relevance between a query and a document is understood by projecting them onto a latent space of entities
- Entity-based: Explicit semantic representations of queries and documents are obtained in the entity space to augment the term-based representations.
The goal of these three approaches is to gain a richer representation of the user’s information needed by identifying entities strongly related to the query.
Balog then identifies six algorithms associated with projection-based methods of entity mapping (projection methods relate to converting entities into three-dimensional space and measuring vectors using geometry).
- Explicit semantic analysis (ESA): The semantics of a given word are described by a vector storing the word’s association strengths to Wikipedia-derived concepts.
- Latent entity space model (LES): Based on a generative probabilistic framework. The document’s retrieval score is taken to be a linear combination of the latent entity space score and the original query likelihood score.
- EsdRank: EsdRank is for ranking documents, using a combination of query-entity and entity-document features. These correspond to the notions of query projection and document projection components of LES, respectively, from before. Using a discriminative learning framework, additional signals can also be incorporated easily, such as entity popularity or document quality
- Explicit semantic ranking (ESR): The explicit semantic ranking model incorporates relationship information from a knowledge graph to enable “soft matching” in the entity space.
- Word-entity duet framework: This incorporates cross-space interactions between term-based and entity-based representations, leading to four types of matches: query terms to document terms, query entities to document terms, query terms to document entities, and query entities to document entities.
- Attention-based ranking model: This is by far the most complicated one to describe.
Here is what Balog writes:
“A total of four attention features are designed, which are extracted for each query entity. Entity ambiguity features are meant to characterize the risk associated with an entity annotation. These are: (1) the entropy of the probability of the surface form being linked to different entities (e.g., in Wikipedia), (2) whether the annotated entity is the most popular sense of the surface form (i.e., has the highest commonness score, and (3) the difference in commonness scores between the most likely and second most likely candidates for the given surface form. The fourth feature is closeness, which is defined as the cosine similarity between the query entity and the query in an embedding space. Specifically, a joint entity-term embedding is trained using the skip-gram model on a corpus, where entity mentions are replaced with the corresponding entity identifiers. The query’s embedding is taken to be the centroid of the query terms’ embeddings.”
For now, it is important to have surface-level familiarity with these six entity-centric algorithms.
The main takeaway is that two approaches exist: projecting documents to a latent entity layer and explicit entity annotations of documents.
Three types of data structures
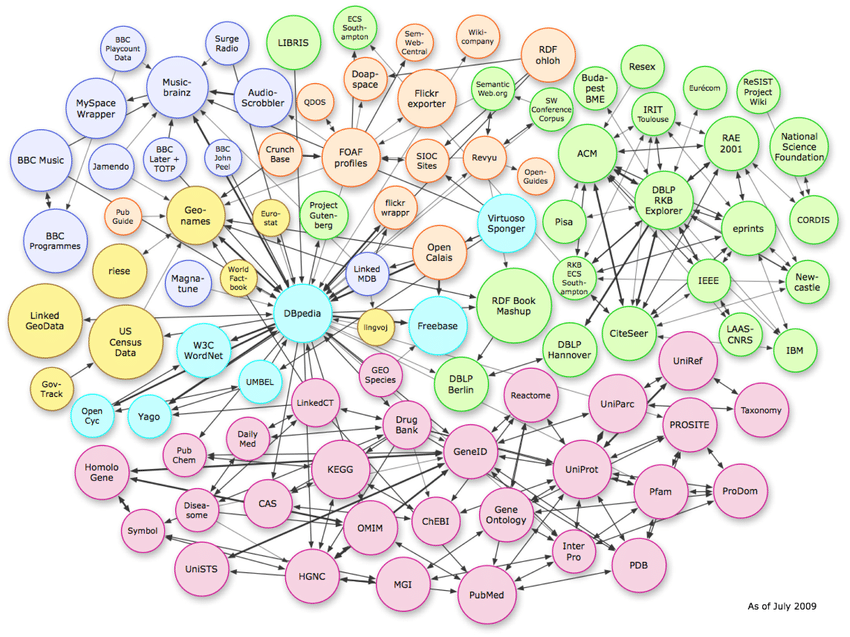
The image above shows the complex relationships that exist in vector space. While the example shows knowledge graph connections, this same pattern can be replicated on a page-by-page schema level.
To understand entities, it is important to know the three types of data structures that algorithms use.
- Using unstructured entity descriptions, references to other entities must be recognized and disambiguated. Directed edges (hyperlinks) are added from each entity to all the other entities mentioned in its description.
- In a semi-structured setting (i.e., Wikipedia), links to other entities might be explicitly provided.
- When working with structured data, RDF triples define a graph (i.e., the knowledge graph). Specifically, subject and object resources (URIs) are nodes, and predicates are edges.
The problem with a semi-structured and distracting context for IR score is that if a document is not configured for a single topic, the IR score can be diluted by the two different contexts resulting in a relative rank lost to another textual document.
IR score dilution involves poorly structured lexical relations and bad word proximity.
The relevant words that complete each other should be used closely within a paragraph or section of the document to signal the context more clearly to increase the IR Score.
Utilizing entity attributes and relationships yields relative improvements in the 5–20% range. Exploiting entity-type information is even more rewarding, with relative improvements ranging from 25% to over 100%.
Annotating documents with entities can bring structure to unstructured documents, which can help populate knowledge bases with new information about entities.
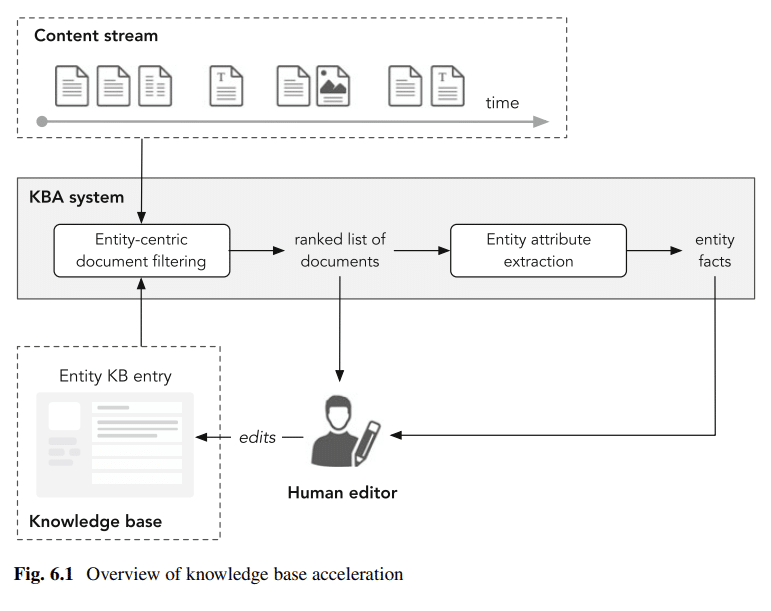
Using Wikipedia as your entity SEO framework
Structure of Wikipedia pages
- Title (I.)
- Lead section (II.)
- Disambiguation links (II.a)
- Infobox (II.b)
- Introductory text (II.c)
- Table of contents (III.)
- Body content (IV.)
- Appendices and bottom matter (V.)
- References and notes (V.a)
- External links (V.b)
- Categories (V.c)
Most Wikipedia articles include an introductory text, the “lead,” a brief summary of the article – typically, no more than four paragraphs long. This should be written in a way that creates interest in the article.
The first sentence and the opening paragraph bear special importance. The first sentence “can be thought of as the definition of the entity described in the article.” The first paragraph offers a more elaborate definition without too much detail.
The value of links extends beyond navigational purposes; they capture semantic relationships between articles. In addition, anchor texts are a rich source of entity name variants. Wikipedia links may be used, among others, to help identify and disambiguate entity mentions in text.
- Summarize key facts about the entity (infobox).
- Brief introduction.
- Internal Links. A key rule given to editors is to link only to the first occurrence of an entity or concept.
- Include all popular synonyms for an entity.
- Category page designation.
- Navigation Template.
- References.
- Special Parsing tools for understanding Wiki Pages.
- Multiple Media Types.
How to optimize for entities
What follows are key considerations when optimizing entities for search:
- The inclusion of semantically related words on a page.
- Word and phrase frequency on a page.
- The organization of concepts on a page.
- Including unstructured data, semi-structured data, and structured data on a page.
- Subject-Predicate-Object Pairs (SPO).
- Web documents on a site that function as pages of a book.
- Organization of web documents on a website.
- Include concepts on a web document that are known features of entities.
Important note: When the emphasis is on the relationships between entities, a knowledge base is often referred to as a knowledge graph.
Since intent is being analyzed in conjunction with user search logs and other bits of context, the same search phrase from person 1 could generate a different result from person 2. The person could have a different intent with the exact same query.
If your page covers both types of intent, then your page is a better candidate for web ranking. You can use the structure of knowledge bases to guide your query-intent templates (as mentioned in a previous section).
People Also Ask, People Search For, and Autocomplete are semantically related to the submitted query and either dive deeper into the current search direction or move to a different aspect of the search task.
We know this, so how can we optimize for it?
Your documents should contain as many search intent variations as possible. Your website should contain every search intent variation for your cluster. Clustering relies on three types of similarity:
- Lexical similarity.
- Semantic similarity.
- Click similarity.
Topic coverage
What is it –> Attribute list –> Section dedicated to each attribute –> Each section links to an article fully dedicated to that topic –> The audience should be specified and definitions for the sub-section should be specified –> What should be considered? –> What are the benefits? –> Modifier benefits –> What is ___ –> What does it do? –> How to get it –> How to do it –> Who can do it –> Link back to all categories

Google offers a tool that provides a salience score (similar to how we use the word “strength” or “confidence”) that tells you how Google sees the content.

The example above comes from a Search Engine Land article on entities from 2018.

You can see person, other, and organizations from the example. The tool is Google Cloud’s Natural Language API.
Every word, sentence, and paragraph matter when talking about an entity. How you organize your thoughts can change Google’s understanding of your content.
You may include a keyword about SEO, but does Google understand that keyword the way you want it to be understood?
Try placing a paragraph or two into the tool and reorganizing and modifying the example to see how it increases or decreases salience.
This exercise, called “disambiguation,” is incredibly important for entities. Language is ambiguous, so we must make our words less ambiguous to Google.
Modern disambiguation approaches consider three types of evidence:
Prior importance of entities and mentions.
Contextual similarity between the text surrounding the mention and the candidate entity and coherence among all entity-linking decisions in the document.
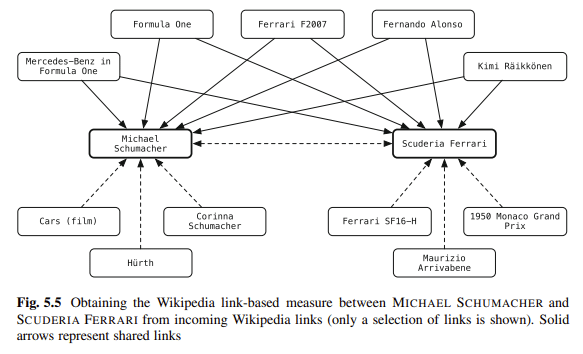
Schema is one of my favorite ways of disambiguating content. You are linking entities in your blog to knowledge repositories. Balog says:
“[L]inking entities in unstructured text to a structured knowledge repository can greatly empower users in their information consumption activities.”
For instance, readers of a document can acquire contextual or background information with a single click, and they can gain easy access to related entities.
Entity annotations can also be used in downstream processing to improve retrieval performance or to facilitate better user interaction with search results.
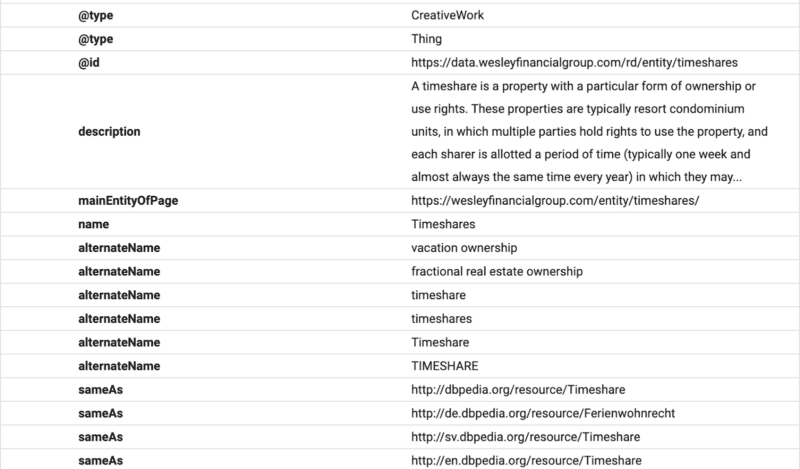
Here you can see that the FAQ content is structured for Google using FAQ schema.
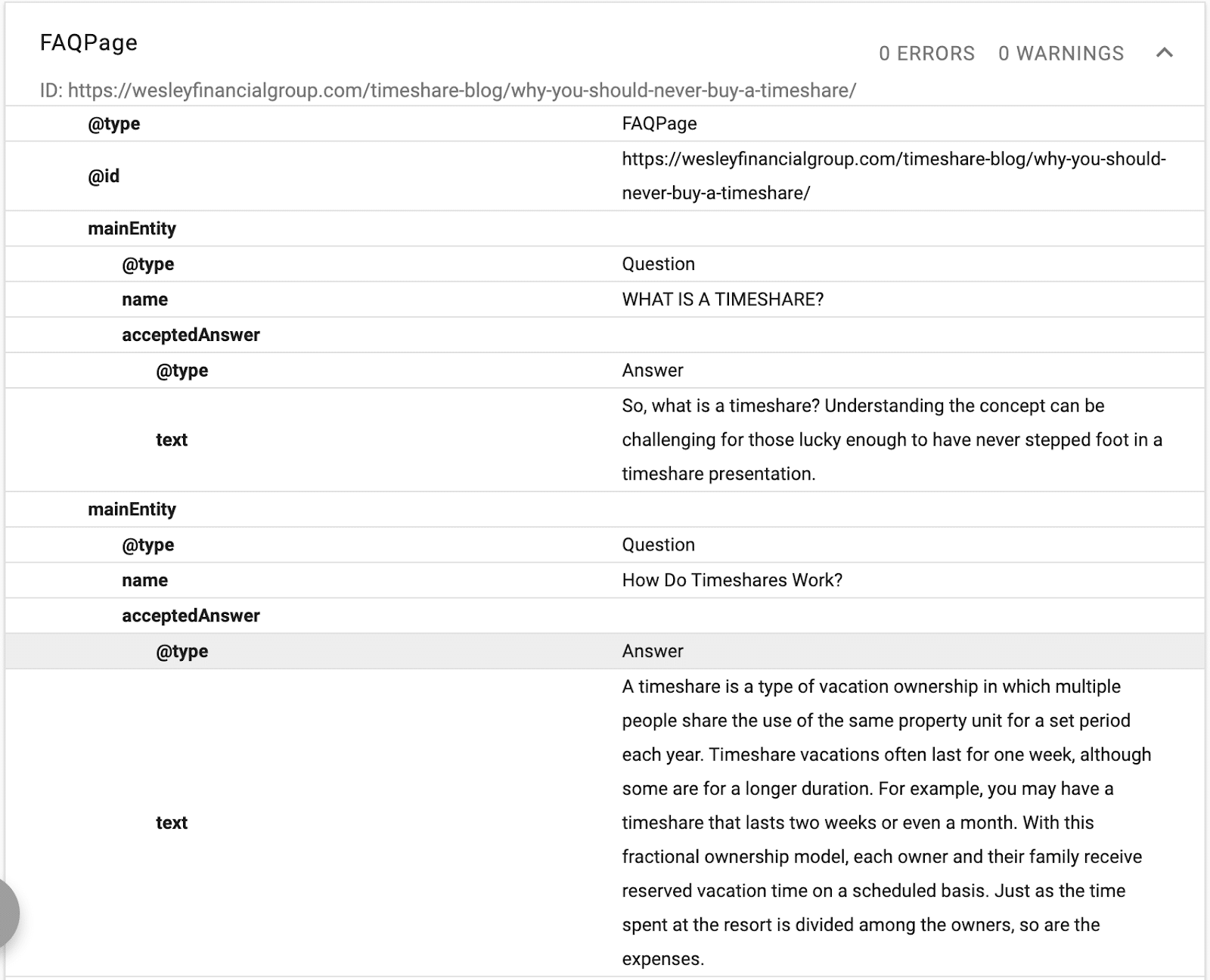
In this example, you can see schema providing a description of the text, an ID, and a declaration of the main entity of the page.
(Remember, Google wants to understand the hierarchy of the content, which is why H1–H6 is important.)
You’ll see alternative names and the same as declarations. Now, when Google reads the content, it will know which structured database to associate with the text, and it will have synonyms and alternative versions of a word linked to the entity.
When you optimize with schema, you optimize for NER (named entity recognition), also known as entity identification, entity extraction, and entity chunking.
The idea is to engage in Named Entity Disambiguation > Wikification > Entity Linking.
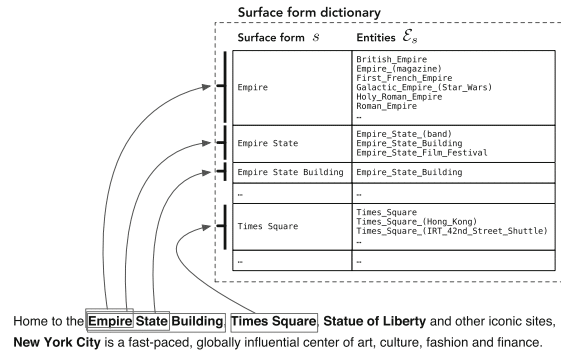
“The advent of Wikipedia has facilitated large-scale entity recognition and disambiguation by providing a comprehensive catalog of entities along with other invaluable resources (specifically, hyperlinks, categories, and redirection and disambiguation pages.”
– Entity-Oriented Search
How to go beyond SEO tool suggestions
Most SEOs use some on-page tool for optimizing their content. Every tool is limited in its ability to identify unique content opportunities and content depth suggestions.
For the most part, on-page tools are just aggregating the top SERP results and creating an average for you to emulate.
SEOs must remember that Google is not looking for the same rehashed information. You can copy what others are doing, but unique information is the key to becoming a seed site/authority site.
Here is a simplified description of how Google handles new content:
Once a document has been found to mention a given entity, that document may be checked to possibly discover new facts with which the knowledge base entry of that entity may be updated.
Balog writes:
“We wish to help editors stay on top of changes by automatically identifying content (news articles, blog posts, etc.) that may imply modifications to the KB entries of a certain set of entities of interest (i.e., entities that a given editor is responsible for).”
Anyone that improves knowledge bases, entity recognition, and crawlability of information will get Google’s love.
Changes made in the knowledge repository can be traced back to the document as the original source.
If you provide content that covers the topic and you add a level of depth that is rare or new, Google can identify if your document added that unique information.
Eventually, this new information sustained over a period of time could lead to your website becoming an authority.
This isn’t an authoritativeness based on domain rating but topical coverage, which I believe is far more valuable.
With the entity approach to SEO, you aren’t limited to targeting keywords with search volume.
All you need to do is to validate the head term (“fly fishing rods,” for example), and then you can focus on targeting search intent variations based on good ole fashion human thinking.
We begin with Wikipedia. For the example of fly fishing, we can see that, at a minimum, the following concepts should be covered on a fishing website:
- Fish species, history, origins, development, technological improvements, expansion, methods of fly fishing, casting, spey casting, fly fishing for trout, techniques for fly fishing, fishing in cold water, dry fly trout fishing, nymphing for trout, still water trout fishing, playing trout, releasing trout, saltwater fly fishing, tackle, artificial flies, and knots.
The topics above came from the fly fishing Wikipedia page. While this page provides a great overview of topics, I like to add additional topic ideas that come from semantically related topics.
For the topic “fish,” we can add several additional topics, including etymology, evolution, anatomy and physiology, fish communication, fish diseases, conservation, and importance to humans.
Has anyone linked the anatomy of trout to the effectiveness of certain fishing techniques?
Has a single fishing website covered all fish varieties while linking the types of fishing techniques, rods, and bait to each fish?
By now, you should be able to see how the topic expansion can grow. Keep this in mind when planning a content campaign.
Don’t just rehash. Add value. Be unique. Use the algorithms mentioned in this article as your guide.
Conclusion
This article is part of a series of articles focused on entities. In the next article, I’ll dive deeper into the optimization efforts around entities and some entity-focused tools on the market.
I want to end this article by giving a shout-out to two people that explained many of these concepts to me.
Bill Slawski of SEO by the Sea and Koray Tugbert of Holistic SEO. While Slawski is no longer with us, his contributions continue to have a ripple effect in the SEO industry.
I heavily rely on the following sources for the article content, as these sources are the best resources that exist on the topic:
- Extended Named Entity Hierarchy by Satoshi Ketine, Kiyoshi Sudo, and Chikashi Nobata
- Entity-Oriented Search by Krisztian Balog, Information Retrieval Series (INRE, volume 39)
- Query Rewriting With Entity Detection, Google Patent
- Refining Search Queries, Google Patent
- Associating An Entity With a Search Query, Google Patent
The post Entity SEO: The definitive guide appeared first on Search Engine Land.
https://ift.tt/YNXitFp
from Search Engine Land https://ift.tt/mAM7lEk
via IFTTT


No comments:
Post a Comment
Thanks and response you soon