




Let’s be honest, JavaScript and SEO don’t always play nice together. For some SEOs, the topic can feel like it’s shrouded in a veil of complexity.
Well, good news: when you peel back the layers, many JavaScript-based SEO issues come back to the fundamentals of how search engine crawlers interact with JavaScript in the first place.
So if you understand those fundamentals, you can dig into problems, understand their impact, and work with devs to fix the ones that matter.
In this article, we’ll help diagnose some common issues when sites are built on JS frameworks. Plus, we’ll break down the base knowledge every technical SEO needs when it comes to rendering.
Rendering in a nutshell
Before we get into the more granular stuff, let’s talk big-picture.
For a search engine to understand content that’s powered by JavaScript, it has to crawl and render the page.
The problem is, search engines only have so many resources to use, so they have to be selective about when it’s worth using them. It’s not a given that a page will get rendered, even if the crawler sends it to the rendering queue.
If it chooses not to render the page, or it can’t render the content properly, it could be an issue.
It comes down to how the front end serves HTML in the initial server response.
When a URL is built in the browser, a front end like React, Vue, or Gatsby will generate the HTML for the page. A crawler checks if that HTML is already available from the server (“pre-rendered” HTML), before sending the URL to wait for rendering so it can look at the resulting content.
Whether any pre-rendered HTML is available depends on how the front end is configured. It will either generate the HTML via the server or in the client browser.
Server-side rendering
The name says it all. In an SSR setup, the crawler is fed a fully rendered HTML page without requiring extra JS execution and rendering.
So even if the page isn’t rendered, the search engine can still crawl any HTML, contextualize the page (metadata, copy, images), and understand its relationship to other pages (breadcrumbs, canonical URL, internal links).
Client-side rendering
In CSR, the HTML is generated in the browser along with all of the JavaScript components. The JavaScript needs rendering before the HTML is available to crawl.
If the rendering service chooses not to render a page sent to the queue, copy, internal URLs, image links, and even metadata remain unavailable to crawlers.
As a result, search engines have little to no context to understand the relevance of a URL to search queries.
Note: There can be a blend of HTML that’s served in the initial HTML response, as well as HTML that requires JS to execute in order to render (appear). It depends on several factors, the most common of which include the framework, how individual site components are built, and the server configuration.
The JavaScript SEO toolkit
There are certainly tools out there that will help identify JavaScript-related SEO issues.
You can do a lot of the investigation using browser tools and Google Search Console. Here’s the shortlist that makes up a solid toolkit:
- View source: Right-click on a page and click “view source” to see the pre-rendered HTML of the page (the initial server response).
- Test live URL (URL inspection): View a screenshot, HTML, and other important details of a rendered page in the URL inspection tab of Google Search Console. (Many rendering issues can be found by comparing the pre-rendered HTML from “view source” with the rendered HTML from testing the live URL in GSC.)
- Chrome Developer Tools: Right-click on a page and choose “Inspect” to open tools for viewing JavaScript errors and more.
- Wappalyzer: See the stack that any site is built on and seek framework-specific insights by installing this free Chrome extension.
Common JavaScript SEO issues
Issue 1: Pre-rendered HTML is universally unavailable
In addition to the negative implications for crawling and contextualization mentioned earlier, there’s also the issue of the time and resources it could take for a search engine to render a page.
If the crawler chooses to put a URL through the rendering process, it will end up in the rendering queue. This happens because a crawler may sense a disparity between the pre-rendered and rendered HTML structure. (Which makes a lot of sense if there’s no pre-rendered HTML!)
There’s no guarantee of how long a URL waits for the web rendering service. The best way to sway the WRS into timely rendering is to ensure there are key authority signals onsite illustrating the importance of a URL (e.g., linked in the top nav, many internal links, referenced as canonical). That gets a little complicated because the authority signals also need to be crawled.
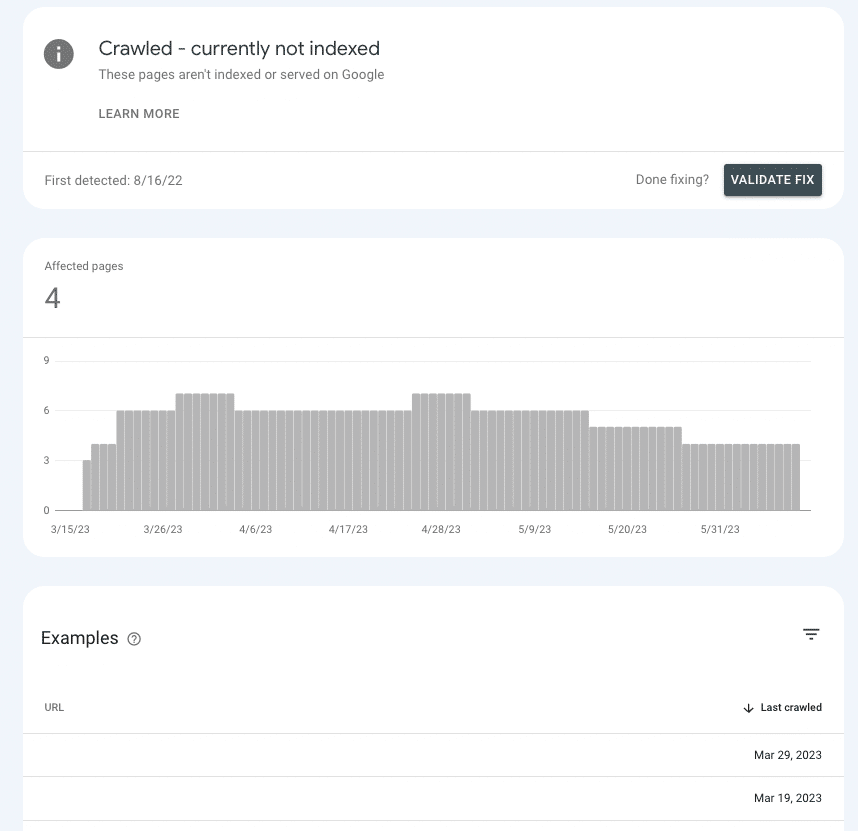
In Google Search Console, it’s possible to get a sense of whether you’re sending the right authority signals to key pages or causing them to sit in limbo.
Go to Pages > Page indexing > Crawled – currently not indexed and look for the presence of priority pages within the list.
If they’re in the waiting room, it’s because Google can’t ascertain whether they’re important enough to spend resources on.
Common causes
Default settings
Most popular front ends come “out of the box” set to client-side rendering, so there’s a fairly good chance default settings are the culprit.
If you’re wondering why most frontends default to CSR, it’s because of the performance benefits. Devs don’t always love SSR, because it can limit the possibilities for speeding up a site and implementing certain interactive elements (e.g., unique transitions between pages).
Single-page application
If a site is a single-page application, it’s wrapped entirely in JavaScript and generates all components of a page in the browser (a.k.a. everything) is rendered client-side and new pages are served without a reload).
This has some negative implications, perhaps the most important of which is that pages are potentially undiscoverable.
This isn’t to say that it’s impossible to set a SPA up in a more SEO-friendly way. But chances are, there’s going to be some significant dev work needed to make that happen.
Issue 2: Some page content is inaccessible to crawlers
Getting a search engine to render a URL is great, only so long as all of the elements are available to crawl. What if it’s rendering the page, but there are sections of a page that aren’t accessible?
For example, an SEO does an internal link analysis and finds little to no internal links reported for a URL linked on several pages.
If the link doesn’t show in the rendered HTML from the Test Live URL tool, then it’s likely that it’s served in JavaScript resources that Google is unable to access.

To narrow down the culprit, it would be a good idea to look for commonalities in terms of where the missing page content or internal links are on the page across URLs.
For example, if it’s an FAQ link that appears in the same section of every product page, that goes a long way in helping developers narrow down a fix.
Common causes
JavaScript Errors
Let’s start with a disclaimer here. Most JavaScript errors you encounter don’t matter for SEO.
So if you go on the hunt for errors, take a long list to your dev, and start the conversation with “What are all these errors?”, they might not receive it all that well.
Approach with the “why” by speaking to the problem, so that they can be the JavaScript expert (because they are!).
With that being said, there are syntax errors that could make the rest of the page unparsable (e.g. “render blocking”). When this occurs, the renderer can’t break out the individual HTML elements, structure the content in the DOM, or understand relationships.
Generally, these types of errors are recognizable because they have some sort of effect in the browser view too.
In addition to visual confirmation, it’s also possible to see JavaScript errors by right-clicking on the page, choosing “inspect,” and navigating to the “Console” tab.
Content requires a user interaction
One of the most important things to remember about rendering is that Google can’t render any content that requires users to interact with the page. Or, to put it more simply, it can’t “click” things.
Why does that matter? Think about our old, trusty friend, the accordion dropdown, and how many sites use it for organizing content like product details and FAQs.
Depending on how the accordion is coded, Google may be unable to render the content in the dropdown if it doesn’t populate until JS executes.
To check, you can “Inspect” a page, and see if the “hidden” content (what shows once you click on an accordion) is in the HTML.
If it’s not, that means that Googlebot and other crawlers do not see this content in the rendered version of the page.
Issue 3: Sections of a site aren’t getting crawled
Google may or may not render your page if it crawls it and sends it to the queue. If it doesn’t crawl the page, even that opportunity is off the table.
To understand whether Google is crawling pages, the Crawl Stats report can come in handy Settings > Crawl stats.
Select Crawl requests: OK (200) to see all crawl instances of 200 status pages in the last three months. Then, use filtering to search for individual URLs or entire directories.

If the URLs don’t appear in the crawl logs, there’s a good chance that Google is unable to discover the pages and crawl them (or they aren’t 200 pages, which is a whole different issue).
Common causes
Internal links are not crawlable
Links are the road signs crawlers follow to new pages. That’s one reason why orphan pages are such a big problem.
If you have a well-linked site and are seeing orphan pages pop up in your site audits, there’s a good chance it’s because the links aren’t available in the pre-rendered HTML.
An easy way to check is to go to a URL that links to the reported orphan page. Right-click on the page and click “view source.”
Then, use CMD + f to search for the URL of the orphan page. If it doesn’t appear in the pre-rendered HTML but appears on the page when rendered in the browser, skip ahead to issue four.
XML sitemap not updated
The XML sitemap is crucial for helping Google discover new pages and understand which URLs to prioritize in a crawl.
Without the XML sitemap, page discovery is only possible by following links.
So for sites without pre-rendered HTML, an outdated or missing sitemap means waiting for Google to render pages, follow internal links to other pages, queue them, render them, follow their links, and so on.
Depending on the front end you’re using, you may have access to plugins that can create dynamic XML sitemaps.
They often need customization, so it’s important that SEOs diligently document any URLs that shouldn’t be in the sitemap and the logic as to why that is.
This should be relatively easy to verify by running the sitemap through your favorite SEO tool.
Issue 4: Internal links are missing
The unavailability of internal links to crawlers isn’t just a potential discovery problem, it's also an equity problem. Since links pass SEO equity from the reference URL to the target URL, they’re an important factor in growing both page and domain authority.
Links from the homepage are a great example. It’s generally the most authoritative page on a website, so a link to another page from the homepage holds a lot of weight.
If those links aren’t crawlable, then it’s a little like having a broken lightsaber. One of your most powerful tools is rendered useless (pun intended).
Common causes
User interaction required to get to the link
The accordion example we used earlier is just one instance where content is hidden behind a user interaction. Another that can have widespread implications is infinite scroll pagination – especially for eCommerce sites with substantial catalogs of products.
In an infinite scroll setup, countless products on a product listing (category) page will not load unless a user scrolls beyond a certain point (lazy loading) or taps the “show more” button.
So even if the JavaScript is rendered, a crawler cannot access the internal links for products yet to load. However, loading all of these products on one page would negatively impact the user experience due to poor page performance.
This is why SEOs generally prefer true pagination in which every page of results has a distinct, crawlable URL.
While there are ways for a site to optimize lazy loading and add all of the products to the pre-rendered HTML, this would lead to differences between the rendered HTML and the pre-rendered HTML.
Effectively, this creates a reason to send more pages to the render queue and make crawlers work harder than they need to – and we know that’s not great for SEO.
At a minimum, follow Google’s recommendations for optimizing infinite scroll.
Links not coded properly
When Google crawls a site or renders a URL in the queue, it’s downloading a stateless version of a page. That’s a big part of why it’s so important to use proper href tags and anchors (the linking structure you see most often). A crawler can’t follow link formats like router, span, or onClick.
Can follow:
- <a href="https://example.com">
- <a href="/relative/path/file">
Can't follow:
- <a routerLink="some/path">
- <span href="https://example.com">
- <a onclick="goto('https://example.com')">
For a developer’s purposes, these are all valid ways to code links. SEO implications are an additional layer of context, and it’s not their job to know – it’s the SEO’s.
A huge piece of a good SEO’s job is to provide developers with that context through documentation.
Issue 5: Metadata is missing
In an HTML page, metadata like the title, description, canonical URL, and meta robots tag are all nested in the head.
For obvious reasons, missing metadata is detrimental for SEO, but even more so for SPAs. Elements like a self-referencing canonical URL are crucial to improving the chances of a JS page making it successfully through the rendering queue.
Of all elements that should be present in the pre-rendered HTML, the head is the most important for indexation.
Luckily, this issue is pretty easy to catch, because it will trigger an abundance of errors for missing metadata in whichever SEO tool a site uses for hygiene reporting. Then, you can confirm by looking for the head in the source code.
Common causes
Lack of or misconfigured metadata vehicle
In a JS framework, a plugin creates the head and inserts the metadata into the head. (The most popular example is React Helmet.) Even if a plugin is already installed, it usually needs to be configured correctly.
Again, this is an area where all SEOs can do is bring the issue to the developer, explain the why, and work closely toward well-documented acceptance criteria.
Issue 6: Resources are not getting crawled
Script files and images are essential building blocks in the rendering process.
Since they also have their own URLs, the laws of crawlability apply to them too. If the files are blocked from crawling, Google can’t parse the page to render it.
To see if URLs are getting crawled, you can view past requests in GSC Crawl Stats.
- Images: Go to Settings > Crawl Stats > Crawl Requests: Image
- JavaScript: Go to Settings > Crawl Stats > Crawl Requests: Image
Common causes
Directory blocked by robots.txt
Both script and image URLs generally nest in their own dedicated subdomain or subfolder, so a disallow expression in the robots.txt will prevent crawling.
Some SEO tools will tell you if any script or image files are blocked, but the issue is pretty easy to spot if you know where your images and script files are nested. You can look for those URL structures in the robots.txt.
You can also see any scripts blocked when rendering a page by using the URL inspection tool in Google Search Console. “Test live URL” then go to View tested page > More info > Page resources.
Here you can see any scripts that fail to load during the rendering process. If a file is blocked by robots.txt, it will be marked as such.

Make friends with JavaScript
Yes, JavaScript can come with some SEO issues. But as SEO evolves, best practices are becoming synonymous with a great user experience.
A great user experience often depends on JavaScript. So while an SEO’s job isn’t to code JavaScript, we do need to know how search engines interact with, render, and use it.
With a solid understanding of the rendering process and some common SEO problems in JS frameworks, you’re well on your way to identifying the issues and being a powerful ally to your developers.
The post A guide to diagnosing common JavaScript SEO issues appeared first on Search Engine Land.
https://ift.tt/N7ovtD0
from Search Engine Land https://ift.tt/4faOBh7
via IFTTT


No comments:
Post a Comment
Thanks and response you soon